Motivation
A common pattern in most data science projects I participated in is that it’s all fun and games until someone wants to put it into production. From that point in time on no one will any longer give you a pat on the back for a high accuracy and smart algorithm. All of a sudden the crucial question is how to deploy your model, which version, how can updates be rolled out, which requirements are needed and so on.
The worst case in such a moment is to realize that up until now the glorious proof of concept model is not an application but rather a stew of Python/R scripts which were deployed by cloning a git repo and run by some Jenkins jobs with a dash of Bash.
Bringing data science to production is a hot topic right now and there are many facets to it. This is the first in a series of posts about data science in production and focuses on aspects of modern software engineering like packaging, versioning as well as Continuous Integration in general.
Packages vs. Scripts
Being a data scientist does not free you from proper software engineering. Of course most models start with a simple script or a Jupyter notebook maybe, just the essence of your idea to test it quickly. But as your model evolves, the number of lines of code grow, it’s always a good idea to think about the structure of your code and to move away from writing simple scripts to proper applications or libraries.
In case of a Python model, that means grouping functionality into different modules separating different concerns which could be organised in Python packages on a higher level. Maybe certain parts of the model are even so general that they could be packaged into an own library for greater reusability also for other projects. In the context of Python, a bundle of software to be installed like a library or application is denoted with the term package. Another synonym is distribution which is easily to be confused with a Linux distribution. Therefore the term package is more commonly used although there is an ambiguity with the kind of package you import in your Python source code (i.e. a container of modules).
So what is now the key difference between a bunch of Python scripts with some modules and a proper package? A Python package adheres a certain structure and thus can be shipped and installed by others. Simple as it sounds this is a major advantage over having just some Python modules inside a repository. With a package it is possible to make distinct code releases with different versions that can be stored for later reference. Dependencies like numpy and scikit-learn can be specified and dependency resolution is automated by tools like pip and conda. Why is this so important? When bugs in production occur it’s incredibly useful to know which state of your code actually is in production. Is it still version 0.9 or already 1.0? Did the bug also occur in the last release? Most debugging starts with reproducing the bug locally on your machine. But what if the release is already half a year old and there where major changes in its requirements? Maybe the bug is caused by one of its dependencies? If your package also includes its dependencies with pinned versions, restoring the exact same state as in production but inside a local virtualenv or conda environment will be a matter of seconds.
Packaging and Versioning
Python’s history of packaging has had its dark times but nowadays things have pretty much settled
and now there is only one obvious tool left to do it, namely setuptools.
An official Python packaging tutorial and many user articles like Alice in Python projectland
explain the various steps needed to set up a proper setup.py
but it takes a long time to really master the subtleties of Python packaging and even then it
is quite cumbersome. This is the reason many developers refrain from building Python packages.
Another reason is that even if you have a correct Python package set up, proper versioning is
still a manual and thus error-prone process. Therefore the tool setuptools_scm exists which
draws the current version automatically from git so a new release is as simple as creating a new tag.
Following the famous Unix principle “Do one thing and do it well” also a Python package is
composed of many specialised tools. Besides setuptools and setuptools_scm there
is sphinx for documentation, testing tools like pytest and tox as well as many other
little helpers to consider when setting up a Python package. Already scared off of Python packaging?
Hold your breath, there is no reason to be.
PyScaffold
Luckily there is one tool to rule them all, PyScaffold, which provides a proper Python package within a second. It is installed easily with
pip install pyscaffold
or
conda install -c conda-forge pyscaffold
if you prefer conda over pip. Generating now a project Scikit-AI with a package skai is just
a matter of typing a single command:
putup Scikit-AI -p skai
This will create a git repository Scikit-AI including a fully configured setup.py that can be configured easily
and in a descriptive way by modifying setup.cfg. The typical Python package structure is provided including
subfolders such as docs for sphinx documentation, tests for unit testing as well as a src
subfolder including the actual Python package skai. Also setuptools_scm is integrated
and other features can be activates optionally like support for Travis, Gitlab, tox, pre-commit
and many more.
An example of a more advanced usage of PyScaffold is
putup Scikit-AI -p skai --travis --tox -d "Scientific AI library with a twist" -u "http://sky.net/"
where also example configuration files for Travis and tox will be created. The additionally provided short description
with the flag -d is used where appropriate as is the url passed by -u. As usual with shell commands,
putup --help provides information about the various arguments.
Versioning
Having a proper Python package already gives us the possibility to ship something that can be installed by others easily including its dependencies of course. But if you want to move fast also the deployment of your new model package needs to be as much automated as possible. You want to make sure that bug fixes end up in production automatically while new features need to be manually approved.
For this reason Semantic Versioning was developed which basically says that a version number is composed of MAJOR.MINOR.PATCH and you increment the:
- MAJOR version when you make incompatible API changes,
- MINOR version when you add functionality in a backwards-compatible manner, and
- PATCH version when you make backwards-compatible bug fixes.
This programming language independent concept also made its way into Python’s official version identification PEP440. Besides MAJOR, MINOR and PATCH the version number is also extended by semantics identifying development, post and pre releases. A package that was set up with PyScaffold uses the information from git to generate a PEP440 compatible, semantic version identifier. A developer just needs to follow the conventions of Semantic Versioning when tagging a release with git.
Versioning becomes even more important when your company develops many interdependent packages. The effort of sticking to the simple conventions of Semantic Versioning right from the start is just a small price to pay compared to the myriad of pains in the dependency hell you will otherwise end up in long-term. Believe me on that one.
Continuous Integration
Now that we know about packaging and versioning the next step is to establish an automated Continuous Integration (CI) process. For this purpose a common choice is Jenkins especially for proprietary software since it can be installed on premise.
Artefact Store
Besides the CI tool there is also a place needed to store the built packages. The term artefact store is used commonly for a service that offers a way to store and install packages from. In the Python world the Python Package Index (PyPI) is the official artefact store to publish open source packages. For companies the on-premise equivalent is devpi that:
- acts as a PyPI mirror,
- allows uploading, testing and staging with private indexes,
- has a nice web interface for searching,
- allows uploading and browsing the Sphinx documentation of packages,
- has user management and
- features Jenkins integration.
If all you care about is Python then devpi is the right artefact store for you. In most companies also Java is used and Nexus often serves thereby already as artefact store. In this case it might be more advantageous to use Nexus also for storing Python packages which is available since version 3.0 to avoid the complexity of maintaining another service.
In highly polylingual environments with many languages like Python, R, Java and C/C++ this will lead to many different artefact stores and various different ways of installing artefacts. A unified approach is provided by conda since conda packages can be built for general code projects. The on-premise artefact store provided by Anaconda is called anaconda-repository and is part of the proprietary enterprise server. Whenever a unified approach to storing and installing artefacts of different languages is a major concern, Anaconda might be a viable solution.
Indices and Channels
Common to all artifact stores is the availability of different indices (or channels in conda) to organize artefacts.
It is a good practice to have different indices to describe the maturity of the contained packages like unstable,
testing and stable. This complements the automatic PEP440 versioning with PyScaffold since it allows us to
tell a development version which passed the unit tests (testing) from a development version which did not (unstable).
Since pip by default installs only stable releases, e.g. 1.0 but not 1.0b3, while the --pre flag
is needed to install unstable releases the differentiation between testing and stable indices is not absolutely
necessary. Still for organisational reasons, having an testing index as input for QA and a stable index that really
only holds releases that passed the whole QA process is a good idea. Also conda does not seem to provide an equivalent
to the --pre flag and thus different channels need to be used.
One should also note that git allows to tag a single commit several times which will lead to different versions of the
Python package having the same content. This gives means to the following convention: Let’s say there was a bug in version
1.2 and after two commits the bug seems to be fixed. The automatically inferred version number by PyScaffold
will be 1.2.post0.pre2-gHASH. Being happy with her fix the developer tags the commit with 1.2.1rc1 (first release
candidate of version 1.2.1). Since all unit tests pass this patch will end up in the testing index where QA can put it to the
acid test. After that, the same commit will be tagged and signed by QA with name 1.2.1 which results in a new package
that can be moved to the stable index automatically.
Automated CI Process
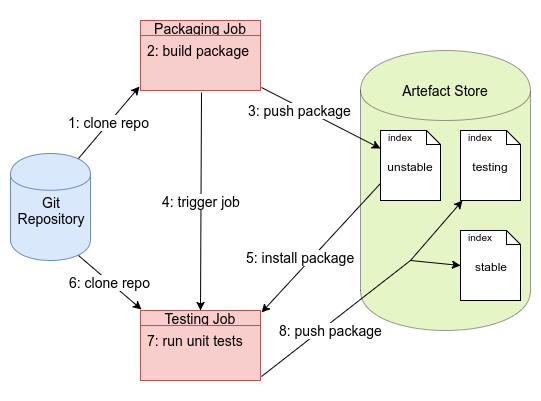
With this components in mind we can establish an automated CI process. Upon a new commit on a central git repository
the packaging Jenkins job clones the repo and builds the package, e.g. with python setup.py bdist_wheel. If this is
successful the package is uploaded to the unstable index of the artefact store. Upon the successful completion of the
packaging job a second Jenkins job for testing is triggered. The reason for packaging and publishing before running
any kind of unit tests is that already during the packaging can be major flaws that a typical unit test could never
find. For instance, missing data files that are in the repo but not specified in the package, missing or wrong
dependencies and so on. Therefore it is important to run unit tests always against the package installed in a clean
environment and that is exactly what the testing job does. After having set up a fresh environment with virtualenv
or conda the just published package is installed from the artefact store.
If this succeeds the git repo is cloned into a subfolder providing
the unit tests (in the tests subfolder). These unit tests are then executed and check the installed package. In case
that all tests pass the package is moved from the unstable index to the testing index. In case the commit was
tagged as a stable release and thus the package’s version is stable according to PEP440 it is moved into the
stable index. Figure 1 illustrates the complete process.
Conclusion
It is clear that packaging, versioning and CI are just one aspect of how to bring Data Science in production and follow-up posts will shed some light on other aspects. Whereas these aspects are quite important, their benefits are often underestimated. We have seen that proper packaging is crucial to shipping, installing a package and dealing with its dependencies. Semantic Versioning supports us in automation of rolling out patches and in the organisation of deployment. The advantages of Continuous Integration are quite obvious and promoted a lot by the DevOps culture in recent years. Also Data Science can learn and benefit from this spirit and we have seen that a minimal CI setup is easy to accomplish. All together they build a fundamental corner stone of Data Science in production. Bringing data science to production plays a crucial part in many projects at inovex since the added value of data science only shows in production.
Some good talks around this topic were held by Sebastian Neubauer, one of the acclaimed DevOps rock stars of Python in production. His talks A Pythonic Approach to CI and There should be one obvious way to bring Python into production perfectly complement this post and are even fun to watch.
Comments
comments powered by Disqus